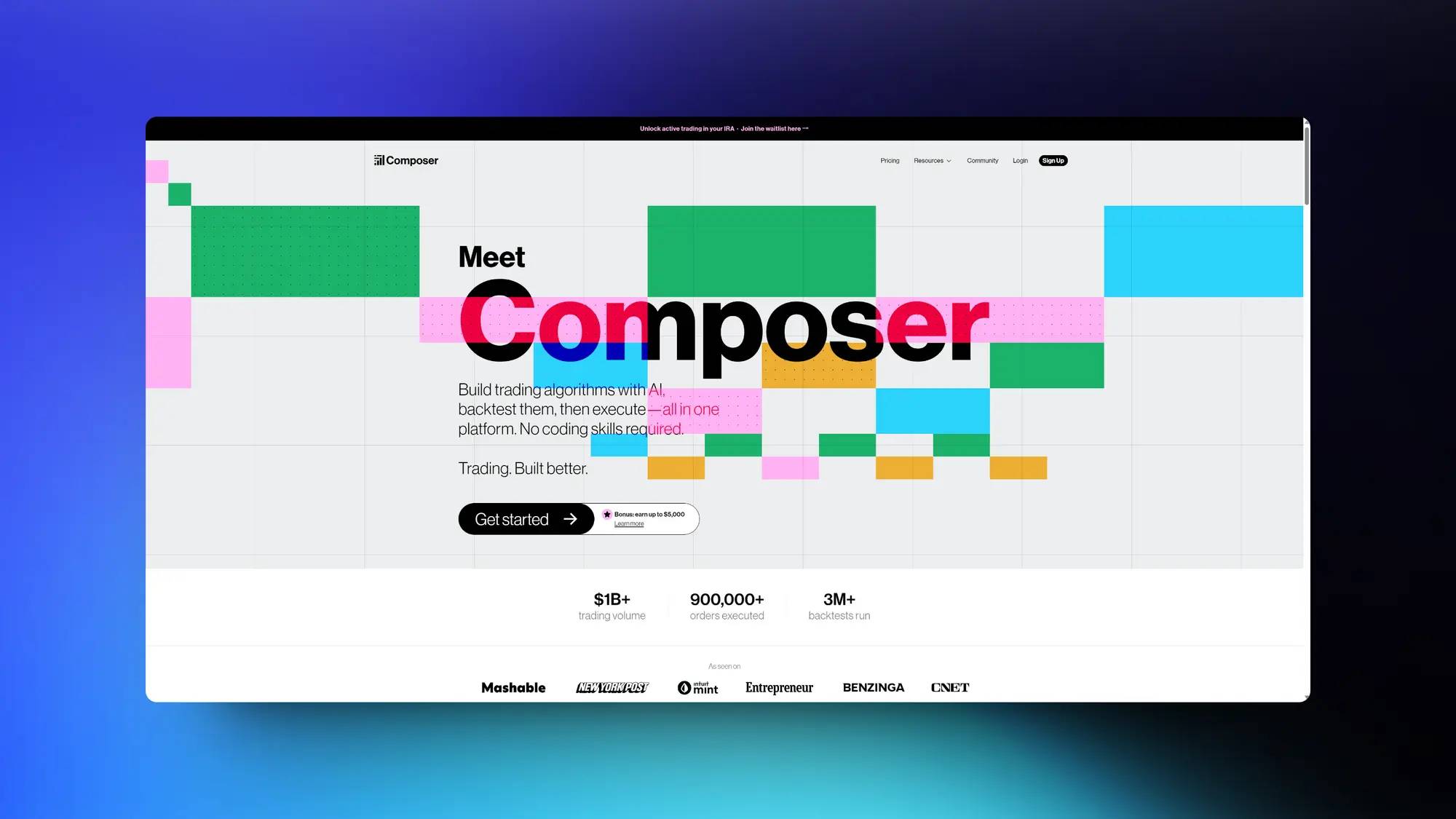
任何有兴趣了解有关训练 Llama 2 的更多信息的人都可能对这个快速指南和视频教程感兴趣,了解如何使用 GPT-4 定制数据集来训练 Meta 最新的大型语言模型。为了帮助完善和简化流程,GPT-llm-trainer 是创新的灯塔,旨在简化创建数据和训练模型的复杂过程。
这个出色的工具专门设计用于自动执行训练大型语言模型过程中涉及的复杂步骤,传统上包括收集数据集、清理数据集、正确格式化数据集、选择模型、编写训练代码,最后训练它。观看下面由提示工程公司精心制作的视频,以了解有关如何自动化 Llama 2 训练过程的更多信息。
GPT-llm-trainer 是一个实验性的新管道,旨在训练高性能的任务特定模型。这个系统的美妙之处在于它能够抽象出所有的复杂性,使其尽可能容易地从一个想法过渡到一个经过充分训练的高性能模型。
使用自定义 GPT-2 数据集训练Llama 4
用户只需输入手头任务的描述,系统就会接管。它从头开始生成数据集,将其解析为正确的格式,并微调LLaMA 2模型,所有这些都是根据用户的特定需求量身定制的。GPT-llm-trainer 拥有多种功能,包括使用 GPT-4 生成数据集。它根据提供的用例创建一系列提示和响应。系统还会为您的模型生成有效的系统提示。
生成数据集后,系统会自动将其拆分为训练集和验证集。然后,它微调模型并为推理做好准备。用户定义提示,这是他们希望经过训练的 AI 执行的操作的描述。用户描述性越强,越清晰,结果就越好。系统需要访问 GPT-4 API 才能创建数据集。
该设置涉及Google Collab笔记本,GPU(最好是付费帐户)和开放的AI API密钥。用户需要提供一个提示,描述他们希望AI做什么,设置温度(控制gpt4的创造力)和示例的数量。
数据创建过程将数据集分为训练集和测试集,其中 90% 的数据用于训练,10% 用于验证或测试。定义了用于训练模型的超参数,包括模型名称、数据集名称和新模型名称。
Prompt Engineering建议使用来自拥抱面的Auto Train Advanced软件包进行微调,因为它允许使用一行代码训练强大的模型。训练需要强大的 GPU,如果用户有访问令牌,则可以使用官方的 llama 2 模型。
总之,GPT-llm-trainer 是一个开创性的工具,它简化了训练模型的过程,使用户能够访问和高效。这证明了人工智能领域的创新力量。